虹膜识别推理的基础理论
简介
随着AI技术的进步,在线上区分人类和机器人变得越来越困难,同时,我们在很多要求非常精确的场景,普通的识别比对已经很难保证。因此,我们提出了一种解决方案,使用 虹膜生物识别技术 来验证真人和识别真人,同时比对。
我们正在一个数十亿人的对抗性环境中构建一个独特性验证系统。 这是对我们生物识别管道的一次技术深度探讨,该系统通过将虹膜纹理编码为虹膜代码来验证独特性。
流程概述
目标是将人的左眼和右眼的高分辨率红外图像转换为虹膜码:一种浓缩的数学和抽象表示,可以用来大规模验证唯一性。 虹膜码由John Daugman引入,并且至今仍然是虹膜识别领域中最广泛使用的虹膜纹理抽象方法。 像大多数最先进的虹膜识别流程一样,我们的流程由四个主要部分组成:分割、归一化、特征提取和匹配。
请参考下图,这是在近红外光谱中获取的虹膜高分辨率图像的示例。 图像的右手边显示了相应的虹膜编码,它本身由 nf=2nf=2 响应映射到两个二维Gabor小波。 这些响应图是量化为两位,因此最终的虹膜代码的尺寸为 nh×nw×nf×2nh×nw×nf×2,有 nhnh 和 nwnw 是应用这些滤波器的径向和角度位置的数量。 虽然我们仅展示了一只眼睛的虹膜编码,请注意虹膜模板由用户双眼的虹膜编码组成。

图1
生物特征识别流程的输入和输出示例。 图 1.a 是由 Orb 拍摄的红外虹膜纹理图像示例。 图1.b是一个虹膜代码的例子,它是由图1.a中的虹膜纹理图像生成的,有效地聚合了虹膜纹理。
在分割步骤中,我们旨在理解输入图像的几何结构。 确定虹膜、瞳孔和巩膜的位置,以及瞳孔的扩张情况和覆盖虹膜纹理的睫毛或头发的存在。 我们的分割模型将图像的每个像素分类为瞳孔、虹膜、巩膜、睫毛等。 然后对这些标签进行后处理,以理解对象眼睛的几何结构。
图像及其几何结构随后通过严格的质量保证。 只有清晰的并且有足够虹膜纹理可见的图像才被视为有效,因为最终虹膜代码中可用位的数量和质量直接影响系统的整体性能。
一旦图像被分割和验证后,归一化步骤将所有与虹膜纹理相关的像素展开成一个稳定的笛卡尔(矩形)表示。
然后在特征提取步骤中,将归一化的图像转换成虹膜代码。 在此过程中,一个Gabor小波核在图像上进行卷积,将虹膜纹理转换成标准化的虹膜代码。 对于图像上的每一个网格点,我们分别导出代表滤波器响应中的实部和虚部符号的两个比特。 这个过程合成了一个独特的虹膜纹理表示,可以轻松地通过使用汉明距离度量与其他虹膜纹理进行比较。 这个度量量化了任何两个比较的虹膜代码之间不同位数的比例。
在以下部分中,我们将通过跟随一个示例虹膜图像在我们的生物识别管道中的旅程,更详细地解释前面提到的每个步骤。 这张图片是在Orb上拍摄的,这是我们的定制生物识别成像设备,由Tools for Humanity (TFH)开发的[8],在我们实验室中进行注册时拍摄的。 它在用户同意的情况下共享,忠实地代表了相机在实时唯一性验证期间看到的内容。
眼睛是一个非凡的系统,表现出各种动态行为,包括眨眼、眯眼、闭眼,以及瞳孔扩张或收缩和睫毛或任何物体遮盖虹膜的能力。 在接下来的部分中,我们将探讨我们的生物特征管道如何在存在这种自然变化的情况下保持稳健。
分割
虹膜识别最早由John Daugmann于1993年开发,虽然自千禧年初以来这一领域已经取得了进展,但它仍然受到传统方法和实践的深刻影响。 历史上,虹膜识别中眼睛的形态是使用经典的计算机视觉方法识别的,例如霍夫变换或圆拟合。 近年来,深度学习在计算机视觉领域带来了显著的改善,提供了全新的工具,以前所未有的深度理解和分析眼睛生理。
我们在研究中提出了一种用于分割高分辨率红外虹膜图像的新方法,我们的架构包括一个由两个解码器共享的编码器:一个估算眼睛几何形状(瞳孔、虹膜和眼球),另一个关注噪音,即覆盖几何形状并可能遮挡虹膜纹理的非眼相关元素(睫毛、发丝等)。 这种二分法允许轻松处理重叠元素,并在训练这些检测器时提供高度的灵活性。 该架构考虑了 DeepLabv3架构,并采用了MobilNet v2主干网。
获取噪音元素的标签比获取几何形状的标签显著耗时,因为它需要高度精确地识别交织在一起的睫毛。 根据模糊程度和受试者的生理状况,标记图像中的睫毛需要20到80分钟,而标记几何形状到我们所需精度水平的时间只需大约4分钟。 因此,我们将噪声对象(例如睫毛)与几何对象(瞳孔、虹膜和巩膜)分离开来,这样可以显著节省资金和时间,同时提高质量。
我们的模型经过了Dice Loss和Boundary Loss的混合训练。 Dice损失可以表示为
LD=∑k(1−2∑i,jyi,j,k⋅pi,j,k∑i,jyi,j,k2⋅∑i,jpi,j,k2)LD=k∑(1−∑i,jyi,j,k2⋅∑i,jpi,j,k22∑i,jyi,j,k⋅pi,j,k)
与以下条件 yi,j,k∈{0,1}yi,j,k∈{0,1} 为独热编码的真实值,并且 pi,j,k∈[0,1]pi,j,k∈[0,1] 模型对像素 (i,j)(i,j) 的输出概率。 第三指标 kk 代表类别(例如,瞳孔、虹膜、眼球、睫毛或背景)。 Dice 损失基本上是测量两个集合之间的相似性,即标签和模型的预测。
准确识别虹膜边界对于成功的虹膜识别至关重要,因为即使边界出现很小的变形,也会导致沿径向方向的标准化图像变形。 为了解决这个问题,我们还引入了一种加权交叉熵损失,重点关注类别之间的边界区域,以鼓励边界更加清晰。 其数学表示为:
LB=∑i,j∑kbi,j,k⋅yi,j,k⋅log(pi,j,k)LB=i,j∑k∑bi,j,k⋅yi,j,k⋅log(pi,j,k)
使用与之前相同的符号表示,并且 bi,j,kbi,j,k 是边界权重,表示像素 (i,j)(i,j) 离类之间的边界的距离 kk 和任何其他类。 我们对轮廓应用高斯模糊,以在保持其周围一般区域较低关注度的同时,优先考虑模型在精确边界上的精度。
bi,j,k=G(d(i,j,Sk))bi,j,k=G(d(i,j,Sk))
与 d(i,j,Sk)d(i,j,Sk) 是点之间的距离 (i,j)(i,j) 和表面之间的距离 SkSk 作为欧几里德距离的最小值在 (i,j)(i,j) 和所有点之间 SkSk. SkSk 是类别之间的边界 kk 和所有其他类别之间的边界, GG 中心在0的一些有限方差的高斯分布。
我们使用其他损失函数(例如凸先验)、架构(例如单头模型)和骨干网(例如ResNet-101)进行了实验,发现此设置在准确性和速度方面表现最佳。 下图显示了由我们的模型预测的分割图覆盖的虹膜图像。 此外,我们显示了在图像捕获阶段由单独的质量评估AI模型计算的标志点。 该模型生成质量指标,以确保在分割阶段仅使用高质量图像,并准确提取虹膜代码以验证唯一性:清晰的图像聚焦在虹膜纹理上,眼睛张开并注视相机等。
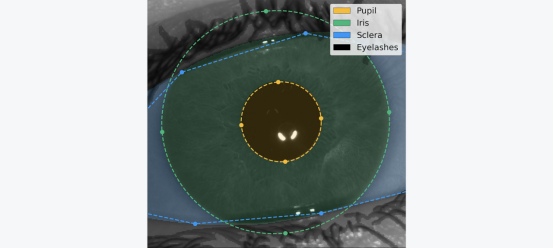
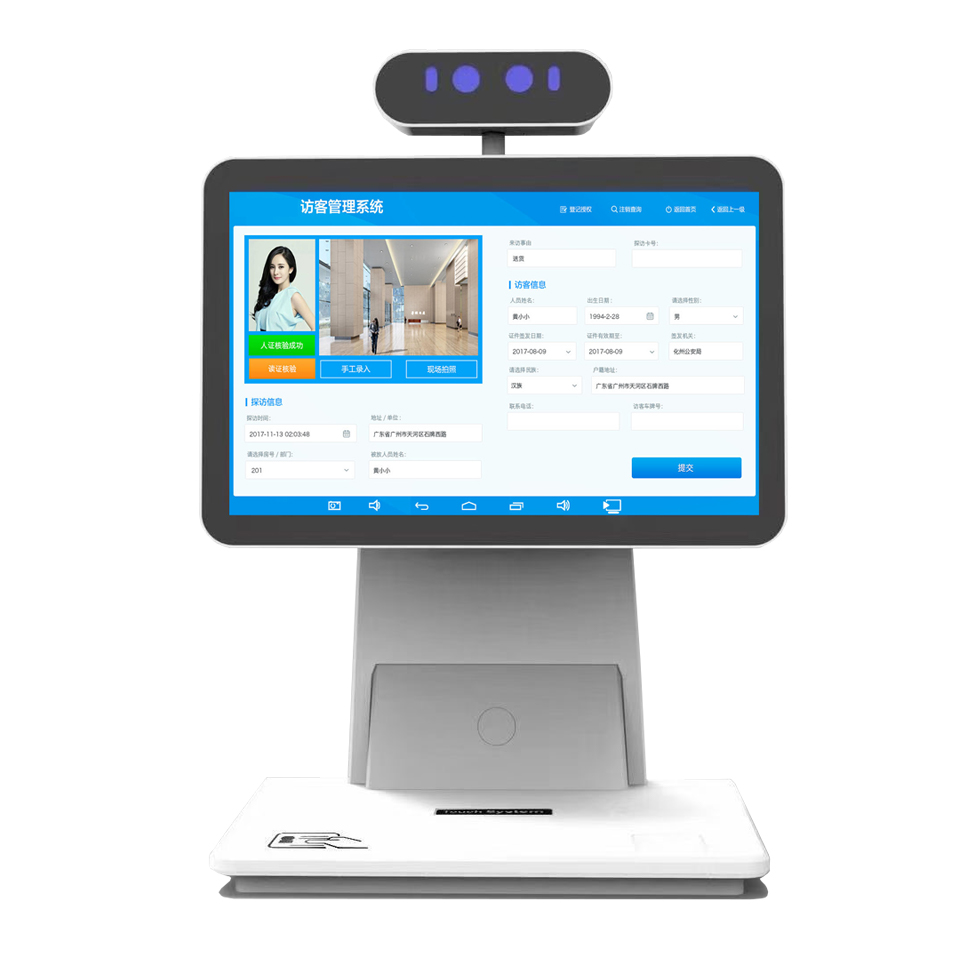
图2
虹膜图像的分割。 我们的AI模型检测眼睛的不同感兴趣区域,以隔离相关的虹膜纹理并评估整体图像质量。 这是在我们实验室中员工注册的结果。
标准化
这一步的目的是从图像的其余部分(皮肤、睫毛、眼球等)中分离出有意义的虹膜纹理。 为此,我们将虹膜纹理从其原始的笛卡尔坐标系统投影到极坐标系统,如下图所示。 虹膜方向定义为从一个瞳孔中心指向另一只眼睛的瞳孔中心的向量。
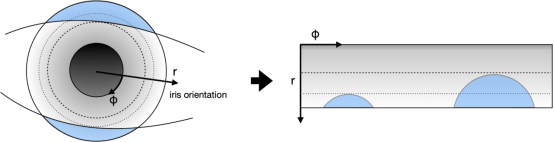
图3
归一化过程示意图。
这个过程通过消除诸如被摄主体与相机之间的距离、由于环境光线多少导致的瞳孔收缩或扩张以及被摄主体头部旋转等变化,减少了图像的可变性。 下图显示了上方虹膜的归一化版本。 图像中可见的两个圆弧是眼睑,它们在归一化过程中从原始形状变形了。
图4
归一化的虹膜纹理。 纹理清晰,其图案清晰可见。
特征提取
现在我们已经生成了稳定的、归一化的虹膜纹理,我们可以计算一个虹膜编码,它可以大规模匹配。 简而言之,我们通过各种Gabor滤波器横跨图像,并对其复值响应进行阈值处理,以提取表示在图像每个选定点存在线条(分别为边缘)的两位比特。 这种技术由约翰·多格曼开创,随后虹膜识别研究社区提出的迭代方案仍然是该领域的最新技术。

图5
最终虹膜代码。 这是表达一个人独特性的匿名化虹膜纹理。
匹配
现在虹膜纹理已被转换为虹膜代码,我们已经准备好将其与其他虹膜代码进行匹配。 为此,我们使用了掩蔽的部分汉明距离(HD):两个虹膜代码中具有相同值的非掩蔽虹膜代码位的比例。
由于Gabor小波的参数化,每个位的值同样可能是0或1。 由于我们的虹膜代码由超过 10,000 位组成,不同个体的两组虹膜代码之间的平均汉明距离为 0.5,大多数 (99.95%) 虹膜代码偏离此值不到 0.05 HD(99.9994% 偏离不到 0.07 HD)。 由于我们比较了多个旋转的虹膜代码,以找到匹配概率最高的组合,这个0.5 HD的平均值移至0.45 HD,伴随着 5.7×10−75.7×10−7 低于0.38 HD的概率。
因此,看到两个不同的眼睛产生距离低于0.38 HD的虹膜代码,是一个极端的统计异常。 相反,同一只眼睛的两幅图像将产生距离通常低于0.3 HD的虹膜代码。 在两者之间应用一个阈值,可以让我们可靠地区分相同和不同的身份。
为了验证我们算法的大规模质量,我们通过收集303个不同受试者的250万对高清红外虹膜图像来评估其性能。 这些受试者代表了包括眼睛颜色、肤色、种族、年龄、有无化妆和眼病或缺陷等各种特征的多样性。 请注意,这些数据不是在我们的实地操作中收集的,而是来源于我们的团队和在受尊敬的合作伙伴组织的专门会议上支付参与者所得。 使用这些图像及其对应的真实身份,我们测量了系统的错误匹配率(FMR)和错误不匹配率(FNMR)。
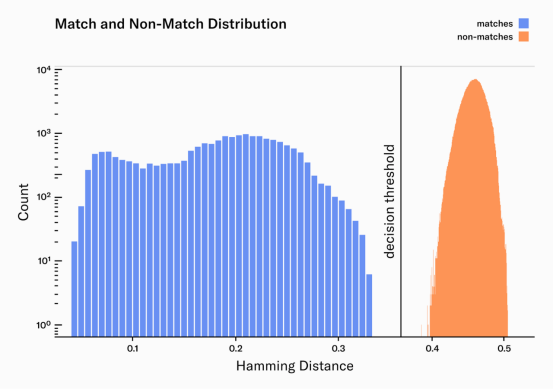
在我们的250万对图像中,所有图像都被正确分类为匹配或不匹配。 此外,匹配和不匹配分布之间的差距很大,提供了一个较大的误差余量以适应潜在的异常值。
匹配分布呈现出两个明显的峰值,或极大值。 左边的峰值(HD≈0.08) 对应于在同一注册过程中从同一人拍摄的图像对的中值汉明距离。 这意味着它们非常相似,就像你预期的那样,来自同一个人的两张图像。 右侧的峰值 (HD≈0.2) 代表了在不同登记过程中拍摄的同一个人的图像对的中位汉明距离,通常相隔数周。 这些图像的相似性较低,反映了同一个人在不同时间拍摄的图像中的自然变化,例如瞳孔扩张、遮挡和睫毛。 我们不断努力改进我们的系统,以缩小匹配分布:更好的自动对焦和AI硬件互动,更好的实时质量过滤器,深度学习特征提取,图像噪声减少等。
由于没有错误分类的虹膜对,我们无法计算 FMR和 FNMR 正是如此。 然而,我们可以估算出两种速率的上限:
FMR=nFMnTM+nFM<12.4⋅107=4.1⋅10−8FMR=nTM+nFMnFM<2.4⋅1071=4.1⋅10−8
FNMR=nFNMnTNM+nFNM<14.1⋅104=2.4⋅10−5FNMR=nTNM+nFNMnFNM<4.1⋅1041=2.4⋅10−5
基于这些数字,我们有信心我们的系统可以在十亿人规模上可靠地验证唯一性,这至少需要 FMR的 10−610−6 和一个相当低的 FNMR 每只眼睛。